
And why your next AI workflow shouldn’t be held hostage by commas.
The Syntax Trap: Why Your AI Agents Hate JSON (And What Comes Next)
And why your next AI workflow shouldn’t be held hostage by commas.

Data formats are the quiet backbone of our financial systems.
We obsess over throughput, KYC rules, security posture, latency SLAs, governance layers… yet the very structure of our data — the braces, tags, whitespace — sits silently behind the curtain, shaping everything the system can and cannot do.
And each time computing took a leap — desktop apps → message buses → REST → microservices → now LLM agents — it demanded a new way of structuring information.
Today, as we plug LLMs into our payments pipelines, fraud engines, loan-origination journeys, customer-experience bots, and internal operations, we are hitting a brick wall:
It’s not because JSON or XML are “bad.” They were perfect for the web and enterprise era.
But we’ve now entered a new era where AI is no longer answering questions — it’s thinking, planning, acting, and collaborating.
This shift exposes a hidden truth:
LLMs struggle not with finance, not with logic, but with syntax.
And that’s why JSON keeps breaking your agent workflows.
Let’s walk through the evolution of data formats — and why a new one, TOON, may be the missing link between AI intelligence might quietly define the next decade of AI in banking.
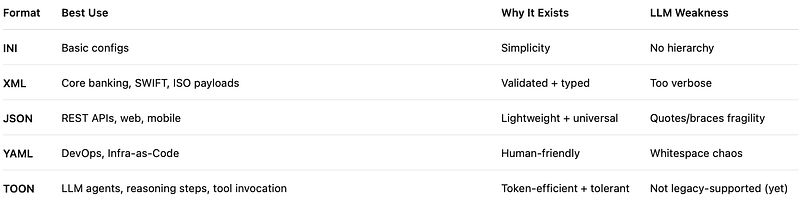
1. INI: The “Index Card” Era
The earliest digital banking systems were simple. An ATM didn’t need nested objects or schema validation. It just needed to know:
- Where is the switch server?
- What cassette holds AED 100 notes?
- Is debug mode on?
So we used INI files — digital index cards.

Why it worked: human-readable and nearly impossible to break.
Why it failed: no hierarchy → couldn’t represent structured financial data (accounts → transactions → balances).
As banks expanded, INI fell apart.
2. XML: The “Bank Vault” Era
Then connectivity arrived: SWIFT, ISO20022, middleware, service buses. Once payment networks, SWIFT channels, ISO 20022, and core banking hubs began integrating, we needed rigour.
No surprises. No guesswork. No silent failures.
XML delivered exactly what banks wanted: schemas, validation, deterministic structure, typed fields, and strict contracts.
A simple balance enquiry became:Banks needed certainty.
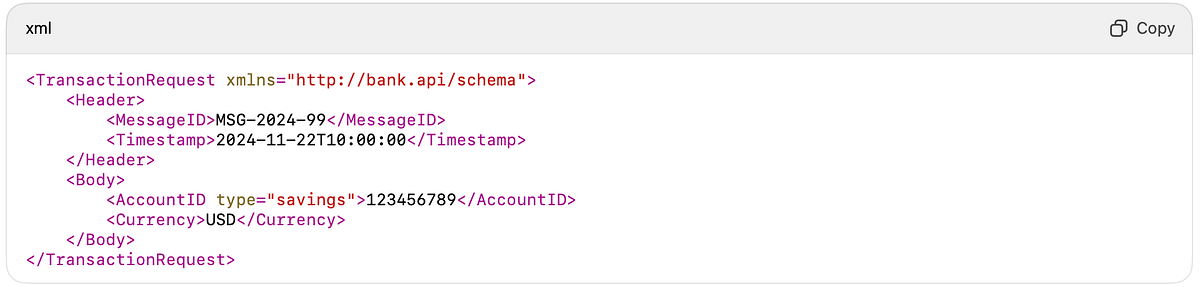
Why it worked: bullet-proof structure — perfect for regulated systems.
Why it failed: expensive to parse, verbosity. Up to 60% of XML is wrapping, not data. When your developers spend more time closing tags than solving problems… something’s wrong.
But XML still powers ISO 20022, SWIFT MX, and core systems today — for good reason.
3. JSON: The “API Courier” Era
Then came mobile apps, browser apps, and cloud banking. Suddenly —
- bandwidth mattered
- APIs exploded
- XML was too heavy
Enter JSON, the courier of the web era.Mobile banking, digital onboarding, open banking, rapid API growth — XML was too heavy.
JSON became the lightweight courier of the web:

Why it worked: lightweight, fast, perfect for REST. For 15 years, JSON was the king of modern banking APIs.
The hidden flaw: JSON is syntactically fragile.
- One missing comma → the entire payload breaks
- One extra quote → 500 error
- Hit a token limit and lose the closing brace → crashed pipeline
Humans misunderstand this. Machines tolerate this.
But LLMs? Chaos. JSON’s strength for deterministic systems becomes a weakness for generative models.
4. YAML: The “Human Era”—and the Silent Killer
DevOps needed something easier to write: Kubernetes, CI/CD pipelines, IaC… all needed human-written configs.
YAML stepped in:

Why it worked: cleaner than
JSON.
Why it failed:
whitespace. One extra space and the structure collapses.
LLMs generating YAML is like asking someone to do neurosurgery wearing oven mitts.
Where Everything Breaks: LLMs + JSON
LLMs do not compute JSON.
They predict text.
And JSON punishes
prediction mistakes.
The LLM JSON Problem

We are forcing an AI to speak a language designed for deterministic compilers. It’s like asking a jazz musician to play inside a filing cabinet.
5. TOON: A Data Format for the Generative Era [ 🎒 Token-Oriented Object Notation ]
If LLMs are becoming the new middleware, we need a format built for:
- token efficiency
- partial generation safety
- semantic clarity
- natural language alignment
- low syntax overhead
That format is TOON — designed specifically for the LLM age.

JSON vs TOON
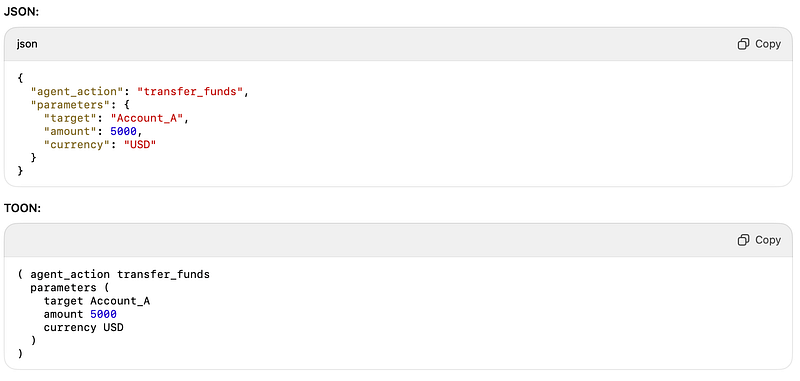
Why TOON works for AI Agents
- Token Efficiency: No quotes, commas, or colons.
- Resilience: Missing characters rarely break the structure.
- Natural Generation: LLMs generate it the same way they generate language.
- Structure Without Noise: The tree holds even if truncated.
At agent-to-agent and model-to-model layers, this matters.
LLMs spend less time fighting syntax and more time reasoning.
Choosing the Right Format
Not everything should move
to TOON.
This is about using
the right tool at the right layer.
The Future: Structure for Systems, Flow for Intelligence
The pattern is clear:
- INI removed hardcoding
- XML removed ambiguity
- JSON removed verbosity
- TOON removes the syntax tax
We do not replace XML in SWIFT messages.
We do not replace JSON in mobile apps.
But for AI Agents that think, plan, and collaborate, forcing JSON is a productivity killer.
The database needs structure.
But the AI needs flow.
If you are building agentic workflows inside a bank — fraud insights, operational copilots, credit decision engines, payment triage agents — stop forcing LLMs to output JSON.
Let them speak a format designed for their brain. That format is TOON.